
こんにちは。開発部の板橋です。
今回は Logstash を用いて Elasticsearch にデータを取り込む作業をします。
① 取り込むデータの準備
今回は以下のような CSV ファイルを取り込みます。
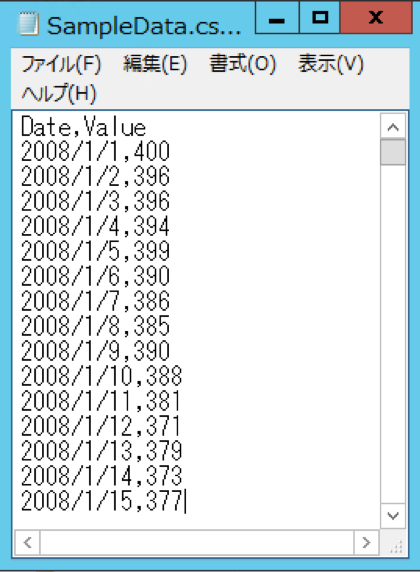
こちらの CSV ファイルは、2008/1/1~2018/12/31 まで、1 日 1 行ずつ記録したものです。
各日付の Value の値は、乱数を用いて生成したものですが、株価や円相場をイメージしていただけるとわかりやすいと思います。
このデータを Elasticsearch に取り込んでいきます。
② CSVファイルの設置
①で用意したファイルを (Logstashのルートフォルダ)/bin に設置します。
③ conf ファイルの用意
Logstash でのデータの取り込み方を指定する conf ファイルを作成します。
今回は以下のファイル SampleData.conf を用意しました。
それぞれの項目について説明します。
ここでは、取り込むデータを指定しています。
path がファイルのパスを、start_position がファイルのどの位置からデータを取り込むのかを指定しています。
ここでは CSV ファイルについて指定しています。
autodetect_column_names => true を指定することにより、CSV ファイルの 1 行目をカラム名として使用できます。
ここではデータの取り込み方を指定しています。
カラム名が Date の要素を、タイムゾーン UT Cで、@timezone という名前に変換して取り込んでいます。
ここでは削除するデータを指定しています。
message は取り込む際に Elasticsearch 側に生成される要素ですが、使わないため削除しています。
Date は上で @timezone として取り込んだため削除しています。
ここではデータの出力について指定しています。
今回は Elasticsearch を 3 台構成にしているのですが、それぞれのサーバーを指定しています。
また、出力される index 名を指定しています。(Elasticsearch では、データは index として保持されます。)
④ Logstash の起動
(Logstashのルートフォルダ)/bin に移動して以下のコマンドを実行し、Logstash を起動します。
Logstash.bat -f SampleData.conf
Logstash が起動すると conf ファイルの指定通りにデータが取り込まれていきます。
Logstash はファイルの最後までデータを取り込んでも、終了せずに残ります。そのため、データ取り込みが終了したあとに CSV ファイルにデータが追加されても、自動でデータの取り込みが行われていきます。
⑤ データの確認
Kibanaのコンソールより、
を実行することで index 名:sampledata_index のデータを確認することができます。
今回取り込んだデータは以下のようになります。
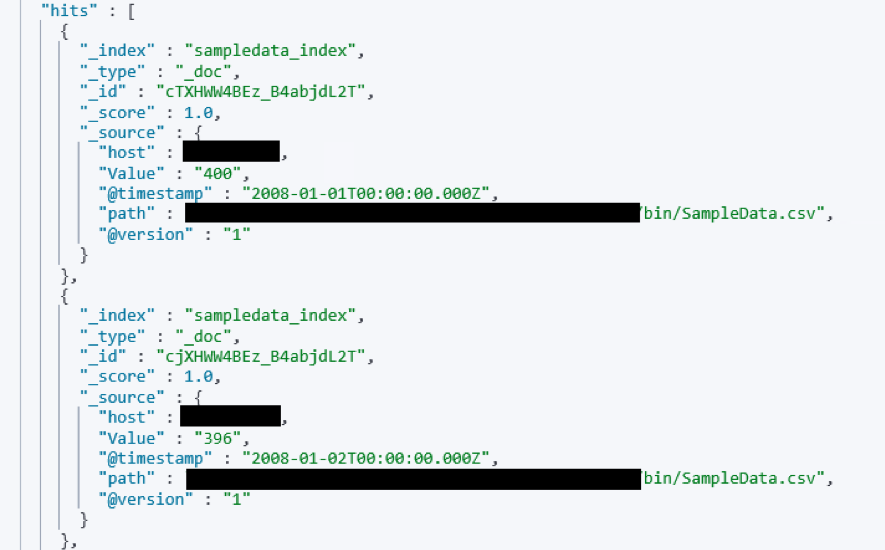
このように Elasticsearch にデータを取り込むことができます。
次回は Kibana を用いて取り込んだデータの可視化を行っていきたいと思います。
ありがとうございました。
<以降の記事>
Elastic Stack を使った予兆検知結果の可視化 〜異常検知の実行〜
Elastic Stack を使った予兆検知結果の可視化 〜検知した異常の通知〜
<前回の記事>
Elastic Stack を使った予兆検知結果の可視化 〜概要と環境構築〜






